
{kind=link}
One of the go-to tools for text editing in Linux is sed, the stream editor. It’s a text editor without an interface that performs operations quietly, straight from the command line. From quick fixes to advanced text transformations, here are nine ways the sed command makes editing easier.
1
Find and Replace Text (Basic and Targeted)
Replacing text is the most common use of sed. I use it most often when working with large files in a terminal because I don’t want to open a separate text editor just for finding and replacing text. Running sed directly from the terminal not only increases my efficiency and speed, but also gives me more customization options than a normal Find and Replace dialog.
The basic syntax for finding and replacing text is simple.
sed 's/old/new/' file.txt
Here, the s command means substitute, old is the text you’re searching for (Flameshot in my case), and new is the text you want to replace it with (e.g. Gradia).
By default, sed replaces only the first occurrence on each line. However, in many situations, you need to swap all occurrences of the targeted word. To do that, add the global flag g at the end:
sed 's/old/new/g' file.txt
Now every occurrence on each line gets replaced.
You can also replace text on a specific line by specifying the line number before the s option:
sed '10s/old/new/' file.txt
This command replaces old text with new text on line 10 only. Similarly, you can replace text within a range of lines by specifying the starting and ending line numbers, separated by a comma, before the s flag:
sed '10,20s/old/new/' file.txt
Beyond line-specific replacements, you can be even more selective by telling sed to act only if a line matches a certain pattern:
sed '/ERROR/s/old/new/g' file.txt
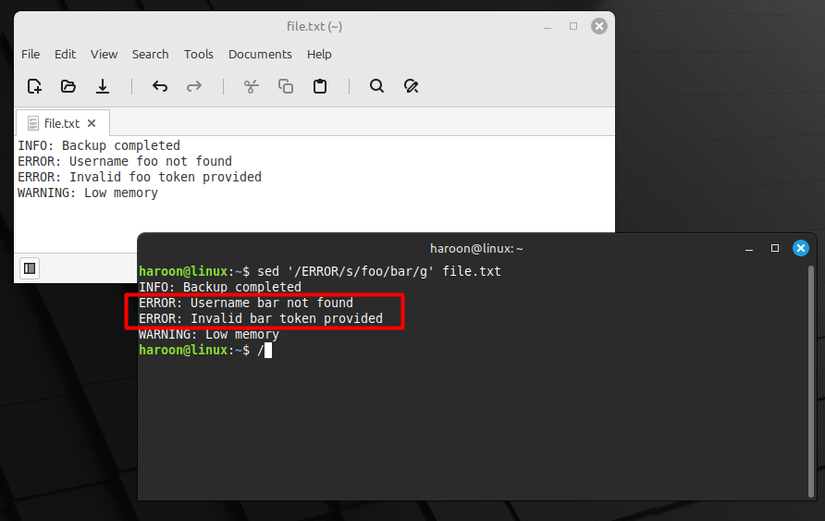
This way, sed replaces text only in lines that match the pattern (like ERROR in this case) while leaving the rest untouched.
2
Inserting, Appending, and Removing Content
While working with files, the three tasks I perform most often are inserting, appending, and removing content. With sed, I can handle all three smoothly and efficiently without ever opening the file in an editor.
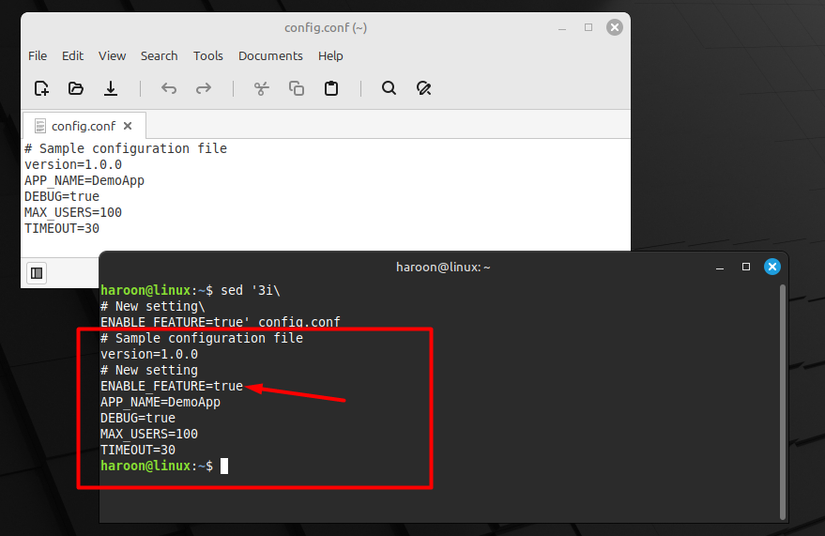
Let’s start with inserting. Using sed, you can add content at any location in the file—before or after a specific line. For example, if you’re working with any configuration file and want to add a new setting before line 3, you can do this with the i flag:
sed '3i\
# New setting\
ENABLE_FEATURE=true' config.conf
Similarly, if you want the text to appear after line 10, just swap i for a:
sed '3a\
Added text' file.txt
The easy way to remember is to think of “i” as insert before and “a” as append after.
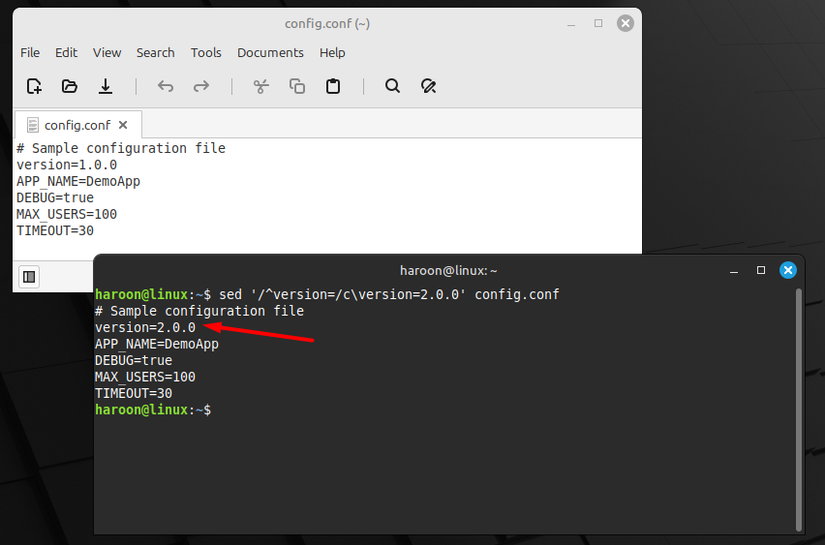
Sometimes it’s cleaner to replace an entire line instead of editing parts of it. For that, use the c option. For example, if you have a properties file with a version number and want to update it, you can replace the whole line:
sed '/^version=/c\version=2.0.0' config.conf
This command deletes the old line and writes your new one in its place.
If you want to remove a line completely without adding anything new, use the d option:
sed '3d' file.txt
That removes line 3. Further, you can also cut out a block of lines by specifying a range like this:
sed '5,10d' file.txt
That clears lines 5 through 10.
Just like earlier, when we used pattern matching for finding and replacing content, we can also use sed for pattern-based deletion. For example, if a log file contains thousands of DEBUG entries, you can remove them all at once:
sed '/DEBUG/d' logfile.txt
These commands might seem intimidating at first, but once you start using them, you’ll quickly perform these basic operations with just a few keystrokes.
3
Displaying and Extracting Content
By default, sed prints every line it processes, which can be overwhelming, especially with logs or configuration files. To control this, we use the -n option, which tells sed to stay quiet unless we explicitly ask it to show something. Pairing this with the p command (for print) gives us full control over what appears.
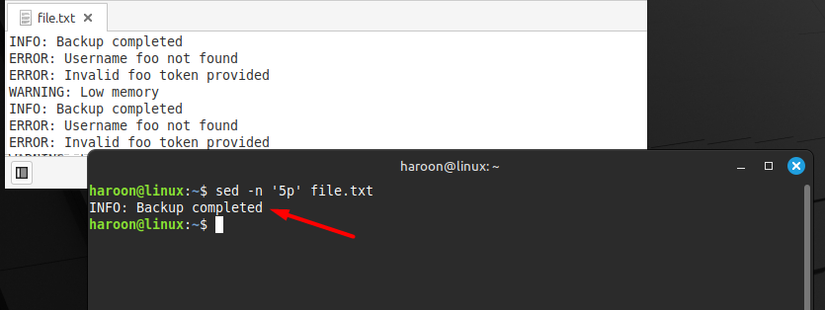
For example, to print the 5th line of a specified file, use:
sed -n '5p' file.txt
You can also grab specific line ranges. For example, to print lines 15 through 20, run:
sed -n '15,20p' file.txt
Similarly, if you’re hunting for a specific word or pattern, such as errors buried in thousands of lines, use this:
sed -n '/ERROR/p' file.txt
Here, sed searches for any line containing the word ERROR and prints only those lines. It’s like running grep, but directly inside sed, which is handy when chaining multiple operations together.
Another powerful use case is extracting chunks of text between two markers. Imagine you’re debugging a system log and only want the section between START and END:
sed -n '/START/,/END/p' file.txt
This command acts like a smart highlighter, pulling out everything between those keywords. To invert the match, simply use the ! option like this:
sed -n '/ERROR/!p' logfile.txt
This prints all lines except those containing ERROR, letting you focus on the clean output and ignore the noise.
4
Modifying Files In-Place With Backup Options
Everything sed does is safe: it only prints results to the terminal, while leaving your original files untouched. However, eventually, you may want to make permanent changes. With the -i option, you can edit the file in place:
sed -i 's/old/new/g' file.txt
This replaces every instance of old with new directly in your text file. No redirection, no extra files, just an instant update. But here’s the catch: this overwrites the file immediately, with no undo button.
To create a backup of the original file, use -i with a backup suffix:
sed -i.bak 's/old/new/g' file.txt
Now, sed creates a copy of the original as file.txt.bak before making edits. If something goes wrong, you can roll back quickly. You can even choose custom suffixes:
sed -i.backup 's/temporary/permanent/g' file.txt
sed -i.$(date +%Y%m%d) 's/foo/bar/g' config.conf
The first command creates file.txt.backup, while the second makes a timestamped backup, a trick I use when iterating over configs, allowing me to trace which version came from which day.
5
Apply Several Changes at Once
Sometimes a single edit isn’t enough. You might be cleaning up a dataset, standardizing labels, or tweaking a config file where multiple changes are needed. Running sed multiple times works, but it’s inefficient. Instead, you can bundle edits together, so the file is scanned only once.
For example, to make two replacements in a single pass, use multiple e flags:
sed -i -e 's/apple/orange/g' -e 's/pear/grape/g' file.txt
Here, the apple becomes orange and pear becomes grape. For a more compact style, you can stack commands in a single string, separated by semicolons:
sed 's/red/blue/g; s/apple/orange/g; /draft/d' data.txt
This version replaces colors, swaps fruit names, and deletes any line containing draft. It works the same way, but as edits pile up, readability suffers. That’s when moving commands into a dedicated script file helps.
6
Automate Edits With Scripts
If you have recurring cleanup tasks, for example, a project with hundreds of files containing minor formatting errors such as extra symbols, inconsistent terms, or stray comments. That’s when you should automate. Instead of pasting lines into your terminal, save your edits in a script file and apply them to any text you need.
For example, create edits.sed with these lines:
s/apple/orange/g
s/pear/grape/g
/^#/d
Now you can run everything at once with:
sed -i -f edits.sed file.txt
With one command, sed applies all your edits in a single pass to your specified file. However, you will need to spend some time creating the edits.sed rules for the files you want to modify.
7
Edit Text by Leveraging Regular Expressions (Regex)
Regular expressions (regex) describe patterns instead of literal text. This means you can target data shapes, such as a word followed by a number or any text at the end of a line, rather than just exact words. At first glance, regex looks intimidating, but once you learn a few basics, it feels like having a Swiss Army knife for text manipulation.
Regex isn’t just for cleaning up text—it also helps you spot patterns and shape how you work with data. Some key symbols include:
- ^ and $ match text at the start or end of a line.
- Square brackets like [0-9] match any digit, and [aeiouAEIOU] help you find or remove vowels.
- The dot . stands for any single character.
- * and + let you repeat patterns as many times as you need.
Regex can get pretty deep, but even learning a few basics opens up a lot of possibilities with tools like sed.
Take this command, which flips first and last names around:
sed -E 's/^([A-Za-z]+)[[:space:]]+([A-Za-z]+)$/\2, \1/' names.txt
If your file looks like this:
John Doe
Jane Smith
Then the output will look like this:
Doe, John
Smith, Jane
Regex also solves consistency problems, like padding single digits with a zero or removing trailing spaces from logs and CSV files:
sed -E 's/\b([0-9])\b/0\1/g' numbers.txt #add a leading zero
sed -E 's/[[:space:]]+$//' file.txt #removing trailing spaces
8
Cleaning and Formatting Text Files
Messy files appear all the time—especially when they come from Windows, Excel, or auto-generated exports. sed quickly cleans that data so you can read, share, or feed it into scripts more easily.
A classic example involves Windows line endings. If you open a Windows file on Linux and see stray ^M characters, that’s the carriage return \r. You can strip the extra carriage return at the end of each line with this:
sed -i 's/\r$//' file.txt
Tabs are another common nuisance. To standardize everything to spaces, you can use this:
sed -E 's/\t/ /g' file.txt
Also, whitespace creeps in everywhere—blank lines, trailing spaces, or inconsistent spacing between words. sed handles it easily with these commands:
sed -E '/^[[:space:]]*$/d' file.txt
sed -E 's/[[:space:]]+$//' file.txt
sed -E 's/[[:space:]]+/ /g' file.txt
Here, the first command cleans up empty lines, the second one strips off stray spaces at the edges, and the last one compresses multiple spaces into a single one for neat, uniform text.
9
Combine With Other Commands
One more thing I love about sed is its ability to work smoothly with other Bash commands. It trims output, extracts information, compares processed files, and scales edits across many files—all with quick one-liners or inside larger scripts.
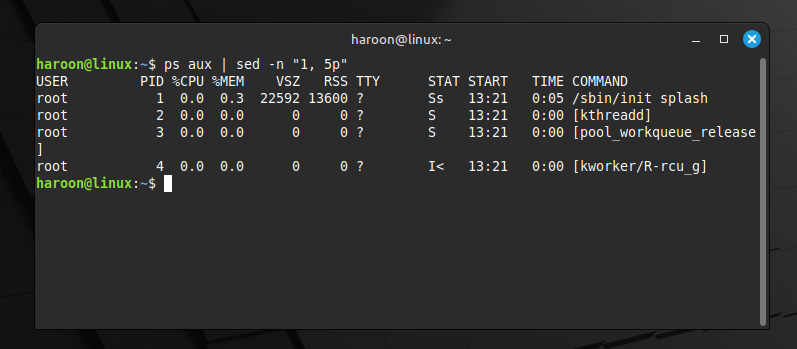
For example, ps aux usually prints more than you want. But piping it into sed keeps just the top five lines:
ps aux | sed -n '1,5p'
You can also combine grep with sed to extract specific information. For instance, if you have a log full of error messages with timestamps in square brackets, use this to extract only the timestamps:
grep 'ERROR' logfile | sed -E 's/.*\[([0-9-: ]+)\].*/\1/p'
These are just a few examples. You can combine sed with diff, find, xargs, and many others. It reshapes complex streams of text, so the next command can do its job better.
From simple find-and-replace operations to complex regex-powered transformations, sed offers solutions that save countless hours of manual work. However, like any Linux command, the key to mastering it is daily practice. Use it often, and soon it will feel like second nature.